Semantic Web, Knowledge Graphs, Social Media and Memes
As a PhD student, I’m keen to discover the latest academic research, which often happens at conferences. Although my main area of research is within marketing, my specialist area is social media. This year I stumbled over the ACM Conference on Hypertext and Social Media.
In case, like me, you didn’t know, the ACM (Association of Computing Machinery) is a major international organisation focused on ‘Advancing Computing as a Science & Profession’. Their members include Vint Cerf, Sir Tim Berners-Lee and many of the computing great and good. They hold 170 conferences a year and have 37 Special Interest Groups, including Hypertext and Social Media.
Academic research source: ACM Digital Library
They also have a Digital Library that contains a wealth of significant academic articles about fake news, analysing Twitter data, bots and big data, privacy and artificial intelligence, as well as every aspect of applied computing and IT you could imagine.
I’ve previously written about the International AAAI Conference on Web and Social Media (ICWSM) and the Academy of Marketing Conference.
The ACM Conference on Hypertext and Social Media took place over 5 days in Prague at the historical Charles University, chaired by Dr Peter Dolog from Aalborg University, Denmark and Professor Peter Vojtas from Charles University, Prague, Czech Republic. The event is partly sponsored by SIGWEB and their representative Professor Ethan Munson explained how SIGWEB was a valuable source of information with the latest academic content on all aspects hypermedia.
What is hypertext? And why does it matter?
Hypertext is a medium (words, images, sound) that contains links. The whole concept of the WWW was built around hypertext – documents that link from one place to another. If you remove hypertext, you end up in a silo that may not contain the real information needed.
What happened to the Semantic Web?
On a related note, another key area is the concept of the semantic web; this was part of Tim Berners-Lee’s original vision for the web and it’s about how data in web pages is structured and how it can be read by computers.
The first keynote at the ACM Conference on Hypertext and Social Media was delivered by Peter Mika of Schibsted who shared his findings on What happened to the Semantic Web?’ Peter provided an overview and explained that back in 2001, Scientific American popularised the semantic web and in the land of search, semantic has grown, partly with rich snippets from Google, Yahoo and Bing. This was closely followed by Pinterest’s rich pins and Facebook’s open graph – it’s all intended to be part of a semantic web.
The issue at the moment is that there are fewer standards, so everyone’s opting for their own system, rather than an open method across all platforms and the result is that web search has become more complex. How many times have you searched for something online, only to find a whole bundle of irrelevant material? This has led to a new area of research ‘semantic search’. The aim is to study retrieval methods where the user intent and resources are represented in a semantic representation, so you’re more likely to get better search results. This is where knowledge graphs appear. Relevant information is linked and used in the search results. So if I search for ‘Bloomingdales New York opening hours’, I’m more likely to get what I was looking for, rather than reviews of the department store. It’s also about how web engineers construct websites to ensure that any possible search data is labelled and tagged correctly.
Knowledge Graphs and Social Media
We wrote about Knowledge Graphs in 2012 and the challenge is that knowledge graphs are private not public – so we have no real opportunity to add to them, other than to edit, as we wrote about in 2016.
One of my interests is social media and the growth of these social networks has led to a more siloed-approach. If I’m in Facebook, I search for content from friends and family and may even read movie reviews, vacation stories and more. The key is that I do all this within one ecosystem, Facebook, rather than crawling across the world wide web, from site to site.
I think of this a little like the all-inclusive holiday. People taking holidays where it’s a fixed price, tend to stay within the resort as they’re already committed (money rather than time) and it’s an easier option. Booking your own flights, accommodation and planning trips, finding and booking restaurants requires more effort and potentially a greater commitment in terms of costs. And social media sites like Facebook are making it easier and easier to stay in the ecosystem; news, trending stories, instant articles – it’s all designed to keep the audience captive for as long as possible.
Peter Mika concluded that the threats were about the monopolisation of the web – largely by social media, but there are opportunities too! Peter mentioned the possibility of standards for sharing user preferences/profiles – privacy was a big theme across the conference – along with open alternatives to Siri/Alexa/Cortana/Google Now, that connect to any (semantic) web service, rather than the specific search engine or location.
A meme is not a virus
The second keynote was delivered by Kristina Lerman; ‘A meme is not a virus: the role of cognitive heuristics in information diffusion’. Starting with the concept of how memes spread online, it’s similar to the outbreak of a virus and her work has looked at standard models of contagion which shows large outbreaks of a virus.
Kristina explained how memes are unlikely to become viral due to various biases and mentioned the cognitive bias codex.
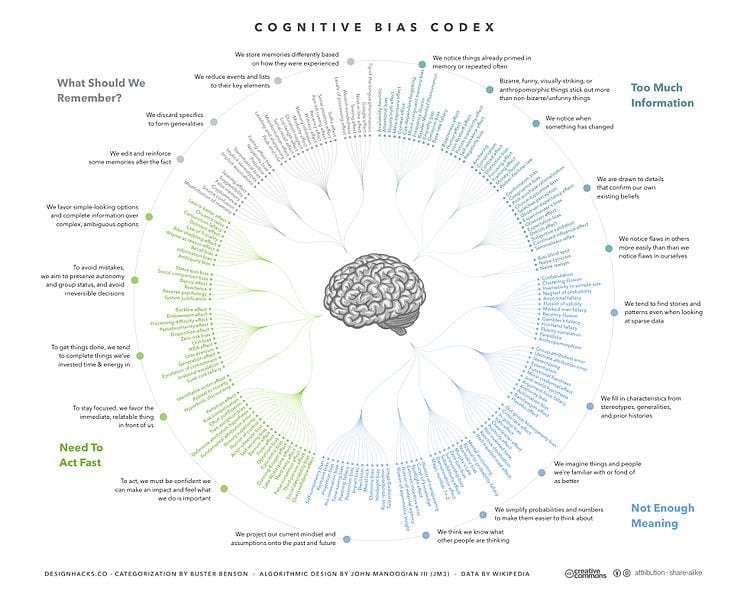
A user needs to see an item and find it interesting before they decide to respond. Looking back at how people make decisions there is a position bias as people pay about 5% more attention to stories at the top of the list! So, if you’re unlucky enough to have content further down the list, it won’t be seen. This is interesting as Facebook focuses on primacy and recency; placing what’s new at the top of the page, emphasising ‘recent content’ and this may be one of the reasons why.
The other issue is in the world of constant content, users divide their attention over all incoming posts, although Kristina mentioned that ‘highly connected people are less sustainable to infection due to their increased cognitive load.’ Effectively people that are well-connected online, are less likely to re-tweet memes, as they are subject to so much additional content. Plus, those with many connections are less likely to re-tweet older posts.
This means that technically, highly connected people suppress the spread of information online. Bizarrely many companies focus on those with large numbers of followers to share their information.
Perhaps they should be looking for those with fewer followers?
Future research to watch
Over the 5 days there were over 35 presentations and too many to list here, so my highlights included:
- Lorena Recalde shared details on how to detect trending topics
- How to classify news outlets using Twitter from @ElejaldeErick
- David Millard, Associate Professor of Computer and Web Science at the University of Southampton and Charlie Hargood shared their Location-Based Narrative using Sculptural Hypertext based on the Tiree Tech Wave (the Isle of Tiree is in Scotland and they have an event on technology every year)
- Ladislav Peska looked at recommender systems
- Mirella Moro explored Point of Interest ratings and reviews
- And a workshop on Immersion in e-Learning was delivered by the enthusiastic Alexandra Cristea from the University of Warwick.
And next year the conference moves from Europe to Baltimore in the USA!






.jpg){kind=link}