A 3 Phased Approach to integrating Content and SEO Audits
In every book about Content Strategy, the recommended process will have an audit as one of the first steps; this is much the same as for Search Engine Optimisation. Granted, there are some specific technical aspects of SEO – particularly regarding server-side issues – that aren't related to content, but SEO audits will also cover onpage issues that need to be forwarded to product or editorial teams. As these disciplines merge, it is useful to get these groups working together, and it saves time to do onpage SEO and content auditing in one go. Thus I suggest combining the audit process as I'll explain here.
Phase One: Gathering Through Crawling
Using Xenu & Excel
Content Strategy books seem slightly wary of using crawlers for content audits. In Content Strategy for the Web, Kristina Halvorson writes (p.48):
"During the audit process… technology can be extremely helpful and, in some cases, necessary. But beware. Technology doesn’t replace the context provided with human review. If you really want an in-depth understanding of your content – substance, quality and accuracy – people power is the best way to go."
But I wouldn’t ever embark on an SEO audit without some sort of robotic assistance, so in this case, it’s vital. I like the SeoMoz crawler (some people prefer Screaming Frog) for spotting things like duplicate content, but since content audits should be able to spot this anyway, I have a preference for Xenu Link Sleuth. The real reason in this preference is speed – you can normally get an up to date crawl report within an hour or two – particularly when you exclude certain directories from the crawl.
You’ll want to eliminate files that are not webpages – images, JavaScript, CSS and other such files are normally contained within earmarked directories or a subdomain. You don’t need to crawl them so put their directories on the exclusion list, and then begin the crawl. If you can’t do this due to URL conventions, you can filter out later.
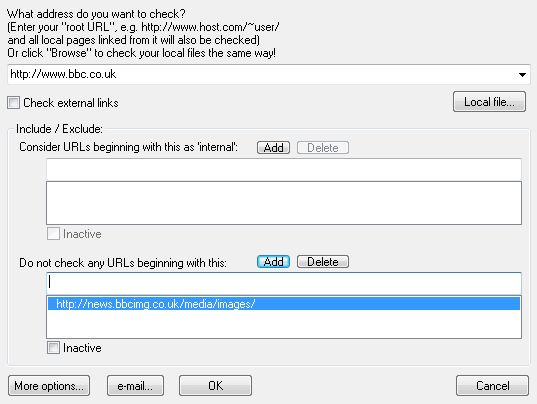
Find the image folder by checking the source of images, and exclude that from the audit. On occasion it may be worth also checking the images.
Phase Two: Creating a Quantitative Audit
Once the crawl has finished, save it as a TAB separated file. Open this up and copy and paste into Excel. If you couldn’t exclude files other than text/HTML during the crawl, you should be able to filter them out from the Type column.
After this step you can hide or lose all of the columns other than:
- Address
- Title
- Description
From here, you should then be able to filter either URL strings or titles into different categories, putting them onto their own sheet. If you can’t (for instance in sites with particularly poor SEO), you will have to do this during the qualitative audit phase.
Finding Duplication
Through doing this, you will almost certainly be able to spot any bad signs of content duplication. Any sections that don’t seem particularly prominent within an Information Architecture, yet have more than their fair share of allotted pages are worth investigating. You will also easily be able to see pagination through checking for parameters such as: ?page= which are always worth checking out.
If You’re Auditing a WordPress Website
On WordPress sites, categorisation often has little to do with URL strings. In this case, it’ll be necessary to crawl each of the various category URLs only – for instance www.carsoncontent.com/blog/category/content-strategy/. Simply place each individual crawl on a separate tab.
Top Level Graph
The Top Level Graph explains the estimated number of articles per category and pageviews. For pageviews, I normally place a UK advanced segment (if using Google Analytics) to get a more accurate number.
You should aim to create a two-in-one bar and line graph. The left axis should indicate page count, the right axis page views. It should look like this:
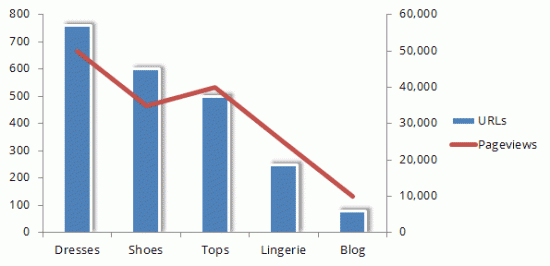
To create a graph like this, you need two data sets next to each other in a table.
- Insert a column chart, then click the lower data series.
- Right click > Format Data series > Plot series on secondary axis.
- Right click the new series > Change Series Chart Type > Select line
Subcategorisation
Once you’ve got a ‘top level’ category listing, you can start ‘subcategorising’ – which is basically stating the topic covered of each piece of content. You could possibly do this by URL strings, but I would take a good look at the content at this stage, because content could have been miscategorised in the past – particularly on larger older sites.
You should give subcategories your best own definition, rather than always using what’s already there, since you’re going to be making a recommendation on how these should be reshaped later anyway.
While doing this, it’s good to assign everything a Unique ID and also note the ‘Content Type’ or format. For instance, is the content a product page, article or gallery?
By now, you should have a table with the following columns:
|
Unique ID
|
URL
|
Page Title
|
Meta Description
|
Category
|
Topic Covered
|
Content Type
|
The URL, Page Title and Meta Description would all have been covered by the Xenu crawl, so you wouldn’t need to fill them out. The rest should be filled out at this stage, but it is just a rough guide. You don’t need to check every URL meticulously. It’s much better to make some assumptions on the content through URLs, Pate Titles or Meta Descriptions – you can always review in the second stage of the audit. Of course, at this stage you may also notice duplication, so you should create another column and add the ID number of the duplicate if something matches the content you are assessing.
COUNTIF
Once you’ve done this, you should be able to make a few graphs to explain counts in Topic Covered and Content Type. Make one count table per category by using the COUNTIF function on the Topic Covered and Content Type columns. Then you can make another graph, indicating which subcategories have the most content:
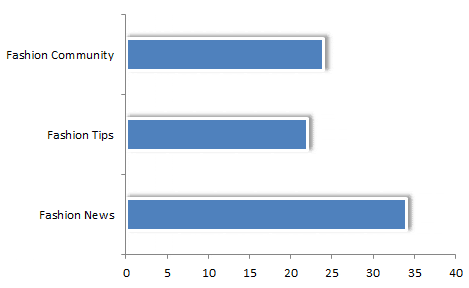
Phase 3: Qualitative Audit
Now you have a feel for how much content sits in which sections, as well as the topics covered, you can begin to look at quality and engagement.
Quality Indicator Columns
First of all, it’s worth bringing some quality indicator columns into your sheets. These are:
- A pageview report from your analytics package for the entire site.
- An inbound links / shares / Page Authority sheet – the most regular source I’d use for this is Opensiteexplorer.org.
You’ll have quite a few sheets of data here, but you really need them all in the same tables. Add the following columns to your tables:
| Unique ID |
URL |
Page Title |
Meta Description |
Category |
Topic Covered |
Content Type |
Duplication |
Pageviews |
Bounce Rate |
External Links |
You can also add social shares if you have that data.
You’ll need to use a VLOOKUP Excel function to import the data. I won’t say how to do that here – but here are two useful resources if you want to learn how:
With these extra columns, you can make quantitated judgements on what’s most important, and what you should focus on reformatting or marking for deletion. However, now you have to look through the content with a rather finer tooth comb.
Note: You could take this further by scraping using XPATH – including bringing in author names, date published or other data. However, our audit document is already getting rather large, and for the purpose of this post, I don’t want to go into scraping as well!
Content Notes
Here you need to add three further columns:
- Action – deems the action for the content. You should have a set list of options: Keep, Reformat, Update, Delete.
- Notes – you may see inconsistencies such as no images or poor formatting which need to be picked up on. For instance, the headline could be weak (and bad for SEO) or there could be style errors.
- Keywords – It’s worth assigning particular relevant keywords to specific rows if you have done a keyword analysis already (I would recommend you do). It means when you come to restructuring or editing the content, all the information will be in one sheet.
You may also want to make notes on pages (or create a column) that could be marked for Schema.org implementation. This isn’t necessary unless your content is relevant to one of the available Schemas.
From here, I would hide all columns apart from the below, else you’ll have a rather distracting and hard to navigate worksheet. You should already know the category simply from the tab.
| Unique ID |
URL |
Topic Covered |
Content Type |
Pageviews |
External Links |
Action |
Notes |
Keywords |
Now you’re auditing the content for quality. I would start with content that has either very low page views or links. This could be due to a problem in the Information Architecture, but it’s more likely that users simply aren’t engaging with that content. If something is viewed very little, but is easy to find, it might be time to mark it for deletion. Sometimes you can do this en mass.
Since you’ve got rid of the deadweight, you should now start looking through each URL to assess content quality, and take notes. It’s crucial here that you match your checks to set criteria – Abhava Leibtag’s Creating Valuable Content Checklist is excellent:

You might notice there are consistent patterns running through content types or even all content. For instance, it’s possible that your site has no HTML styling! If this happens, you may as well forget about marking content for ‘Reformat’, since this will be required for everything.
A Note on Site Size
Websites are often very big – and many are above 5,000 pages. It’s possible for one person to run through all of the above on a site of 5,000 pages, but it would likely take them five uninterrupted days, and by the end of it they might be getting a little jaded. Try and break it up by giving different audit sections to different team members.
Conclusion: The Graft
Doing an audit on this scale might seem gruelling, but you’ll need to assess a good sample of any site for content subject matter, quality and engagement if you’re looking to improve both SEO and content. I would normally assume an auditor to be able to get through around 1,000 pages per day – so a 5,000 page site may take a whole week! If this is too long, try focusing on the most highly engaged content by pageviews and most linked to – since these will almost certainly be the most important. But still, through this process you will gain an in depth understanding of how the current content is structured, a vital step in making required improvements to the Information Architecture.





